有一个需求,需要对不同规格的包裹进行定价,在Excel里输入长宽高和重量,即可自动计算出定价信息。
但是包裹的尺寸和重量同时决定了定价。定价是分段计算的,包裹将根据尺寸和重量范围分为不同的包裹类型,比如有信件包裹、标准包裹、大尺寸包裹等。在每一个包裹类型下,对于不同的包裹重量,又有不同的定价标准。
我们举例说明。
假设有一个包裹标准:
1、小尺寸包裹:30 * 20 * 10 cm,5 kg;其中,小于等于2.5kg定价2元,小于等于5kg定价4元。
2、中尺寸包裹: 40 * 30 * 20 cm, 10 kg;其中,小于等于5kg定价5元,小于等于10kg定价10元。
3、大尺寸包裹:60 * 40 * 30 cm, 20 kg;其中,小于等于5kg定价10元,小于等于10kg定价15元,小于20kg定价25元。
解释如下:当一个包裹最大边长小于等于30cm,且第二边长小于等于20cm,且最小边长小于等于10cm,且最大重量不超过5kg时,该包裹被视为小尺寸包裹。当前述任意一个条件不满足于小尺寸要求时,将被自动划为下一级包裹判断,当下一级包裹尺寸标准仍不满足时,将被自动划为下下一级包裹判断。
按照该标准,
1、一个尺寸61 * 14 * 8 cm重量3kg的包裹将被划分为大尺寸包裹,定价为10元。
2、一个尺寸29 * 15 * 10 cm重量6kg的包裹将被划分为中尺寸包裹,定价10元。
如果你对这个计价方式感到熟悉,是的,这就是亚马逊FBA配送费的计价模式。
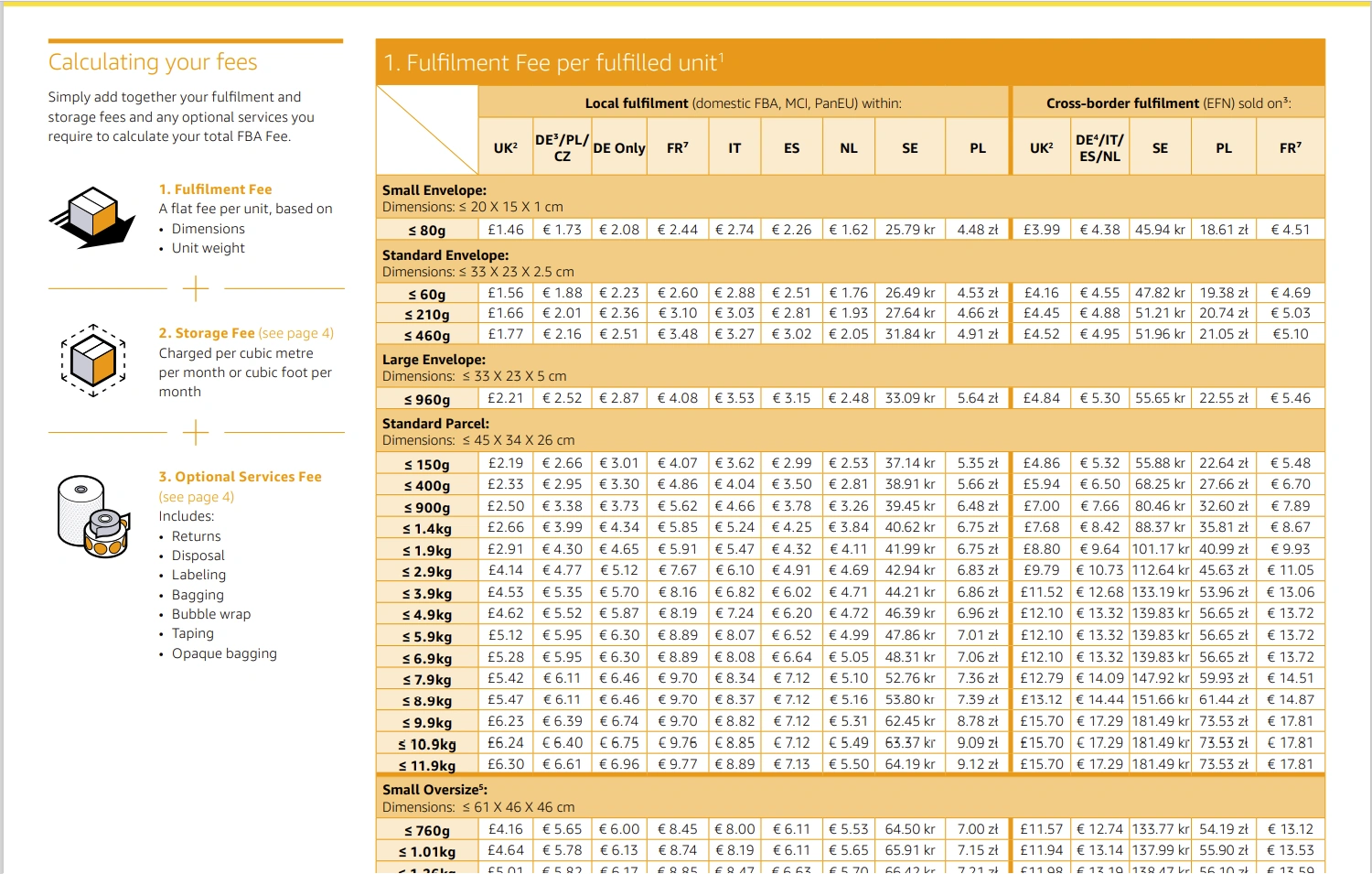
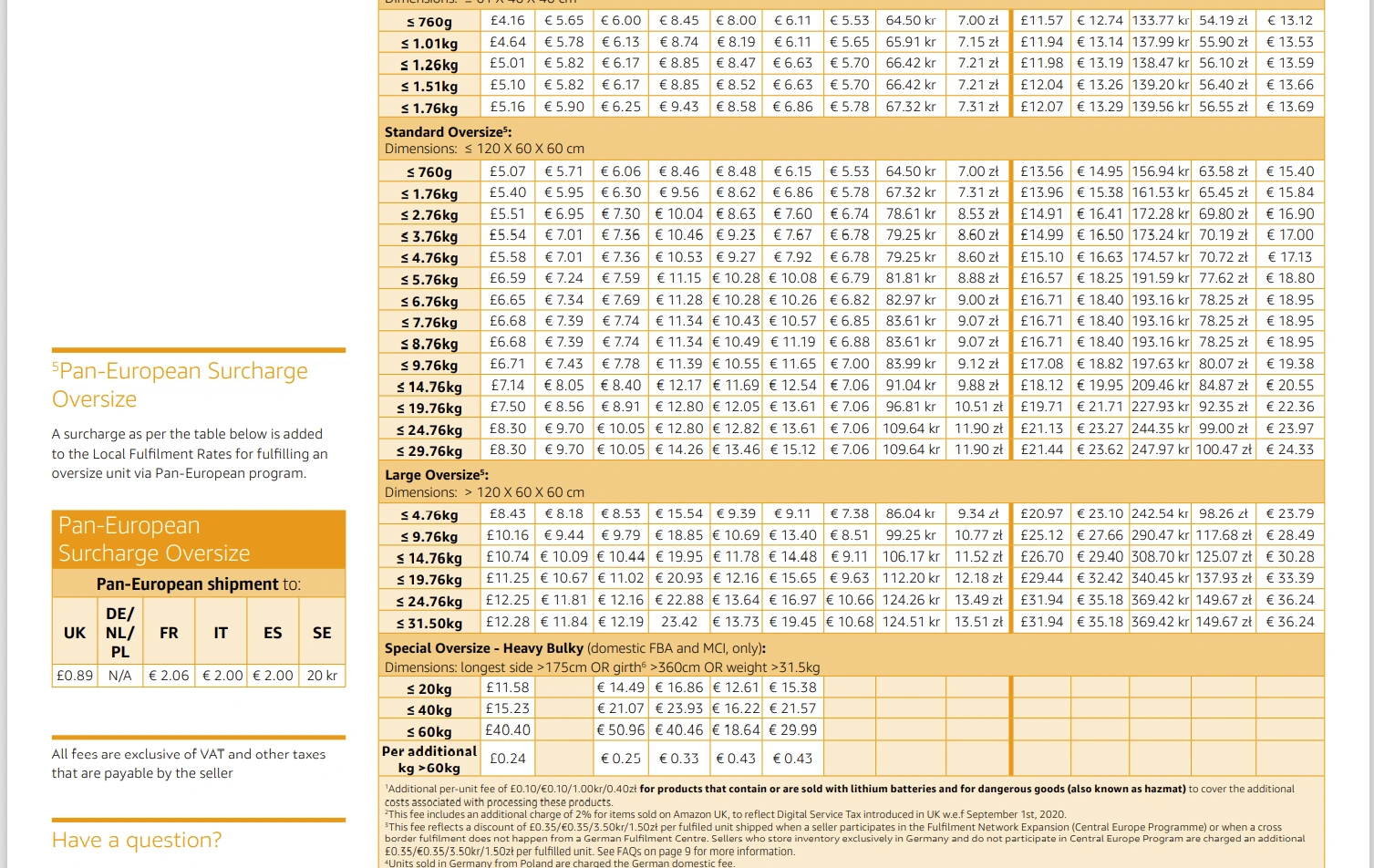
文章开头的需求是,利用这套计价表的标准,在Excel中填入包裹长宽高和重量,将自动匹配报价区间获得配送报价,同时我们还要考虑到,对长宽高的定义容错,一个29 * 15 * 10 cm重量6kg的包裹与一个15* 10 * 29 cm重量6kg 的包裹,本质上,是一样的。
这是我给自己提的需求,因为我实在懒到不想手动去查报价。
这一切必须都在Excel实现,并且使用纯函数公式实现,不使用VBA。这种分段计价方式如果用代码实现其实是最容易想的,不过我VBA很少用,另外用VBA实现是一种非常笨重的做法,缺乏灵活性。我还要求,报价表可以灵活删改,增加报价区间、去掉报价区间不影响整体函数的执行。以下为我的需求细则:
1、L、W、H属性容错,数据位置不影响包裹类型和报价结果。
2、纯函数公式实现。
3、规范化的报价表格,支持修改和删减。
4、可以方便地实现功能复用。
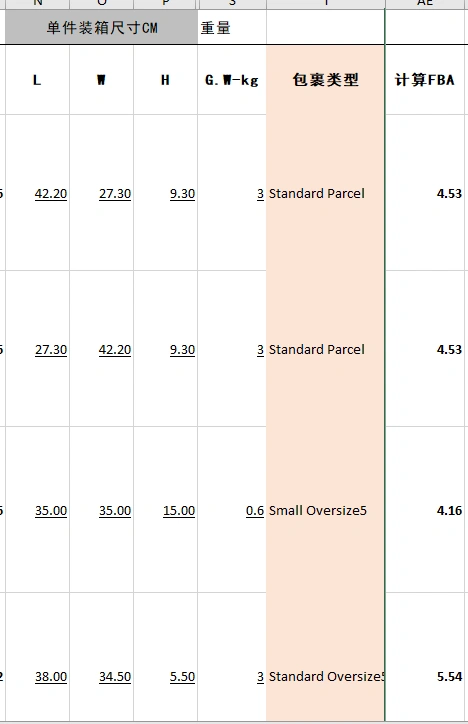
今天偷偷摸鱼了一下,居然真的就实现了。
那么如何实现的呢?
本文将涉及到以下知识点:
1、LARGE()或SMALL()函数
2、数组公式
3、表格样式
4、名称管理
5、数据分列
6、INDEX()和MATCH()组合公式
7、数据清洗技巧
软件环境:
Office 2019
Windows 10 64bit
数据清洗与数据匹配表生成
亚马逊只提供了PDF价目表,我们需要做的第一件事就是把PDF转化为标准化的数据表。
1、使用Adobe Acrobat DC Pro 将PDF直接转为Excel。
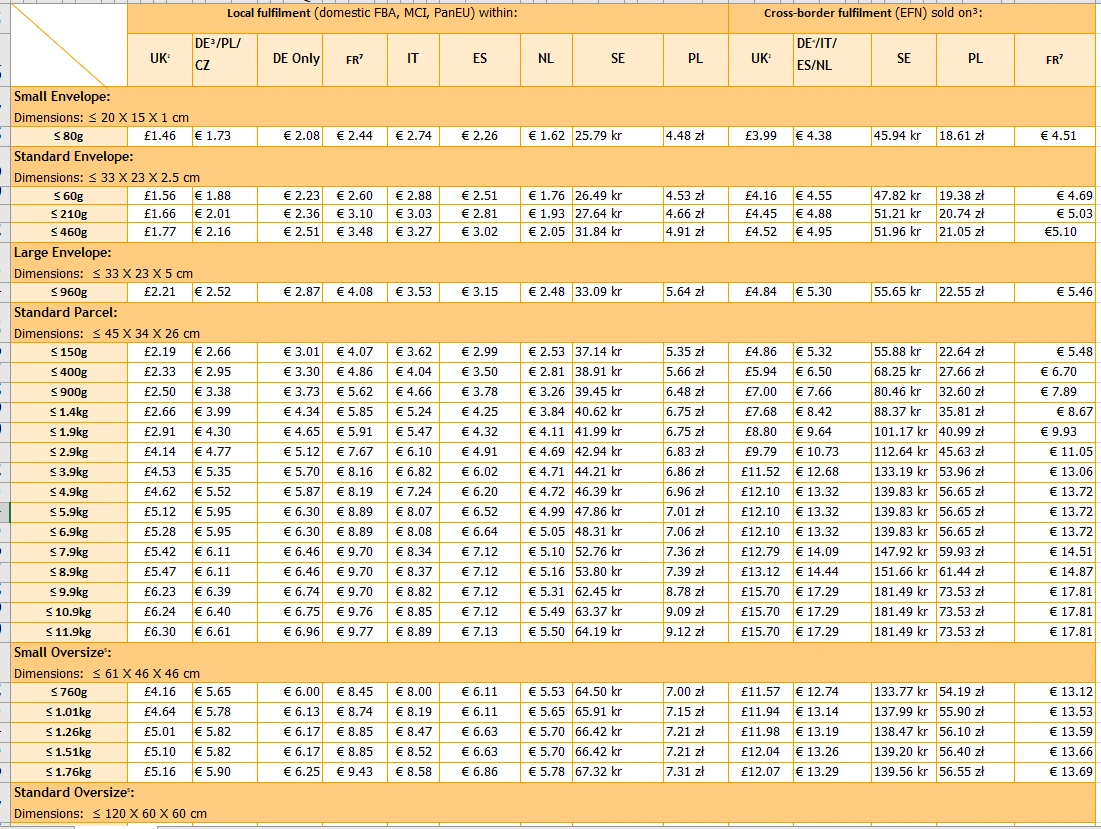
2、生成的Excel不能直接使用,需要数据清洗。大概就是👇:
a、去掉样式,去掉空白行列。
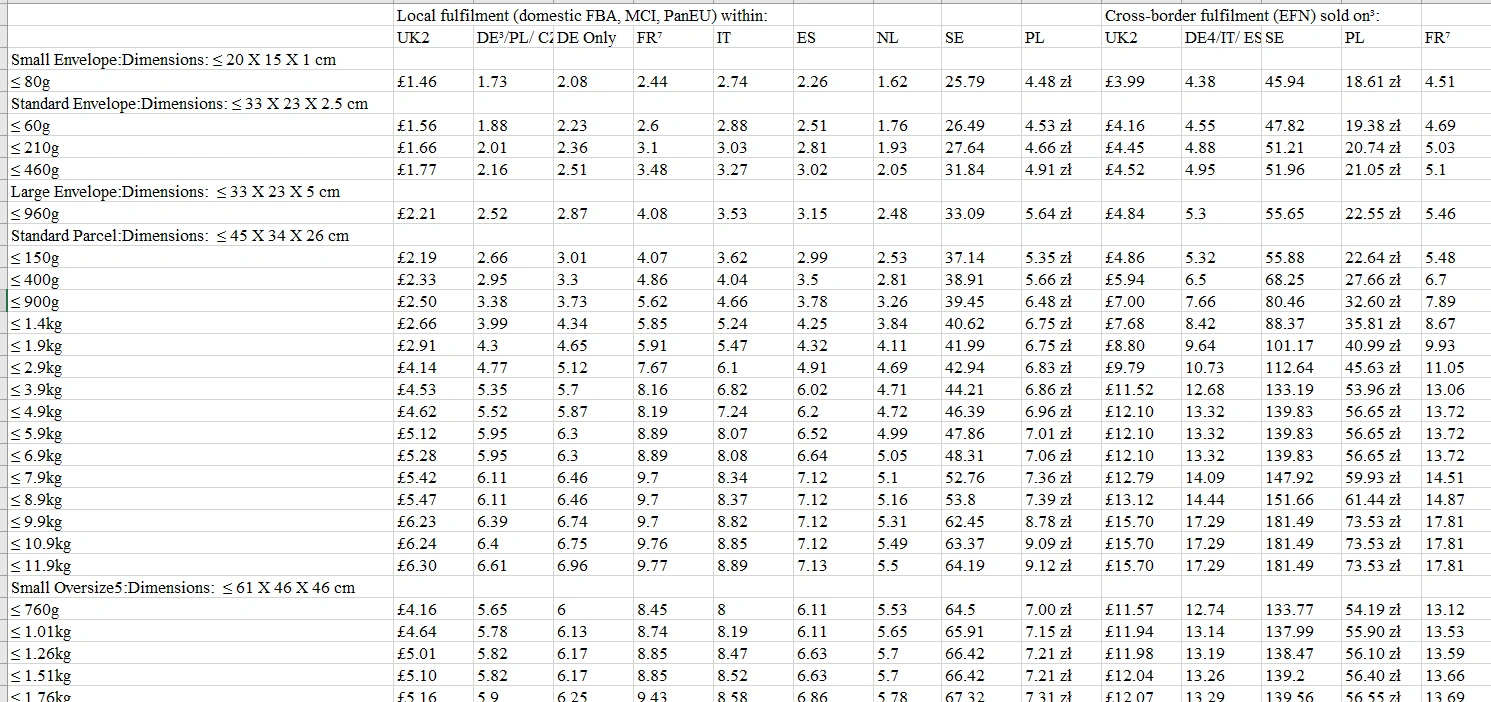
b、替换无法识别的字符,数据转为纯数字。
c、从文本中识别数据,比如要将9行和11行的包裹类型、长、宽、高提取出来,转化为我们需要的标准化数据表格式,这种格式能够被函数识别并匹配包裹类型和报价。

最后会变成这样:

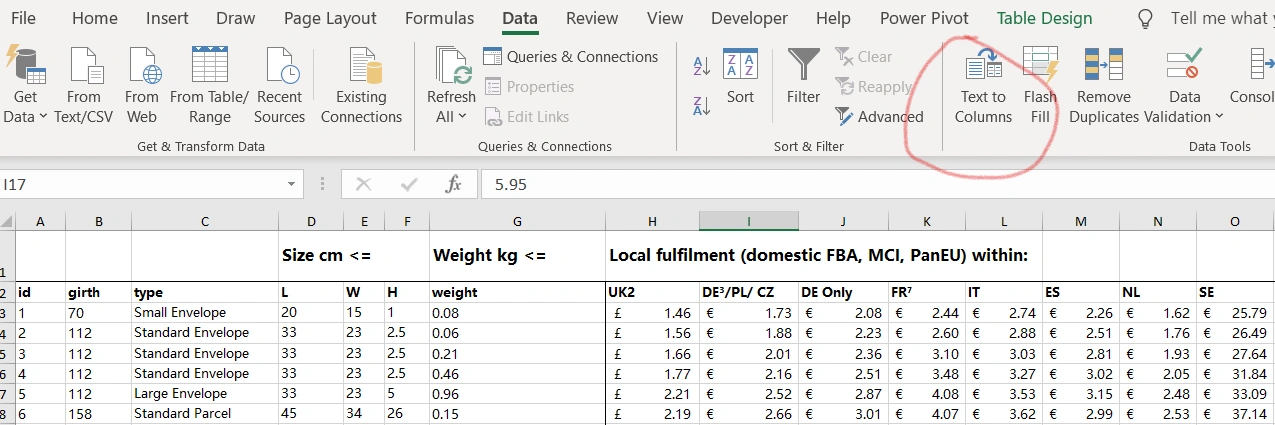
提供个思路,Excel中的数据-分列功能可以很方便地将文本数据分列:
如果读者读者还是觉得麻烦,我们可以在Google Sheets中使用正则表达式函数提取数据。
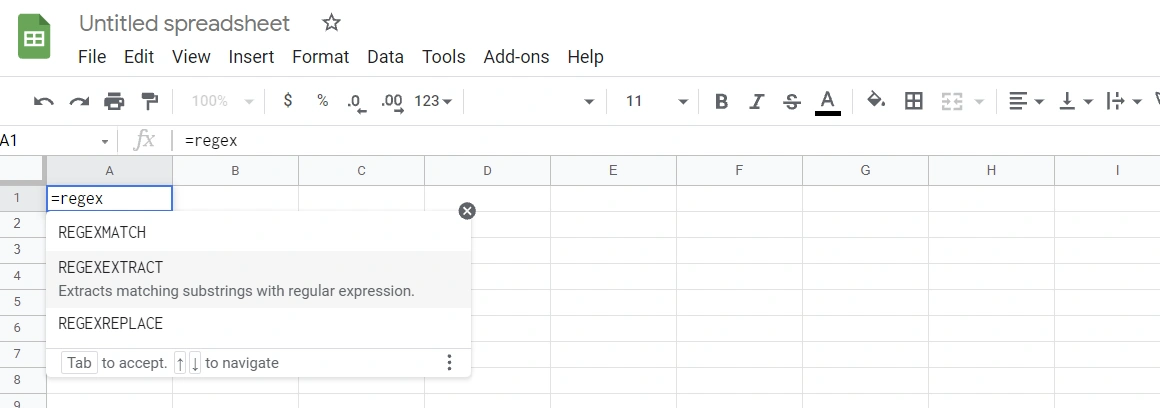
可以看到我加了girth字段,因为FBA大尺寸包裹还需要考虑到Girth。
最后我们生成标准化数据匹配表,应注意的是,数据是从上到下依次递增的,有时这对于INDEX()和MATCH()函数组合非常重要。
在这里我需要说明表格样式和名称管理的概念。
表格样式
一个表在转为表格(table)之前,只能被视为区域(range),当我们引用数据时,只能通过单元格进行引用,区域引用的缺点是:
1、不直观,且非常容易出错。
2、数据引用固定,无法动态更改。
3、无法把区域视为一个整体,当区域内容发生变化时,无法同步变化。
将区域转化为表除了解决以上问题外,还有以下好处:
1、可以方便导入power query,并且动态更新表范围。
2、不需要选择区域,即可方便地对表内数据筛选、排序。
3、新增行时自动填充公式和同步样式。
将区域转化为表格的方式是使用表格样式,主页-表格样式。
名称
当一个区域被转化为表格时,就被赋予了一个名称。一个名称还可以代表一张表格、一个区域、一列、一行、一个单元格、一个公式、一个数据。
名称也是为了动态引用而存在的,同时也保证了数据的直观,使用名称的好处与使用表的好处类似。
我们可以在公式-名称管理器中管理名称。
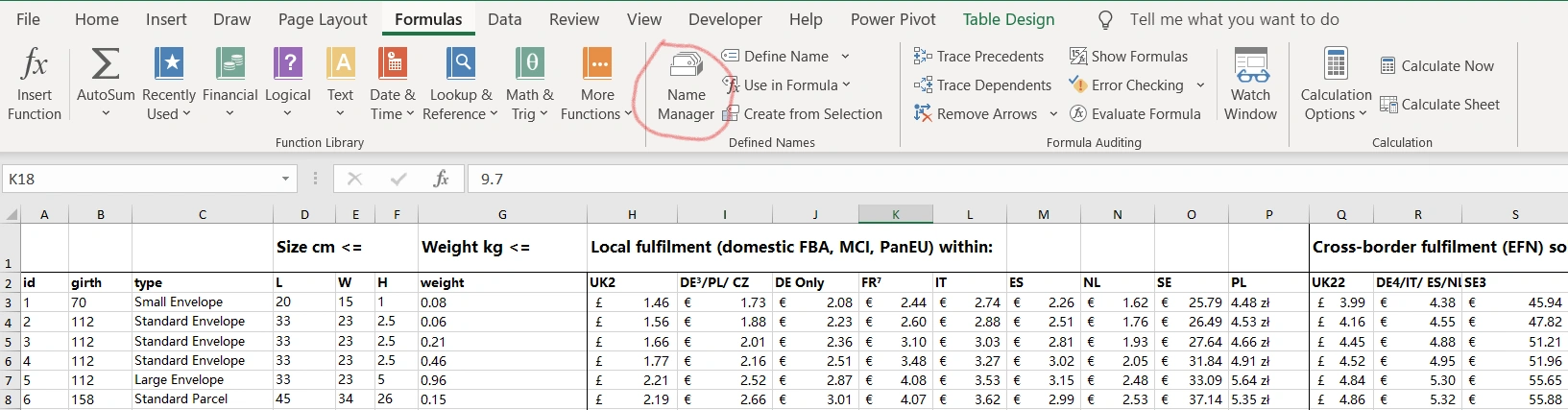
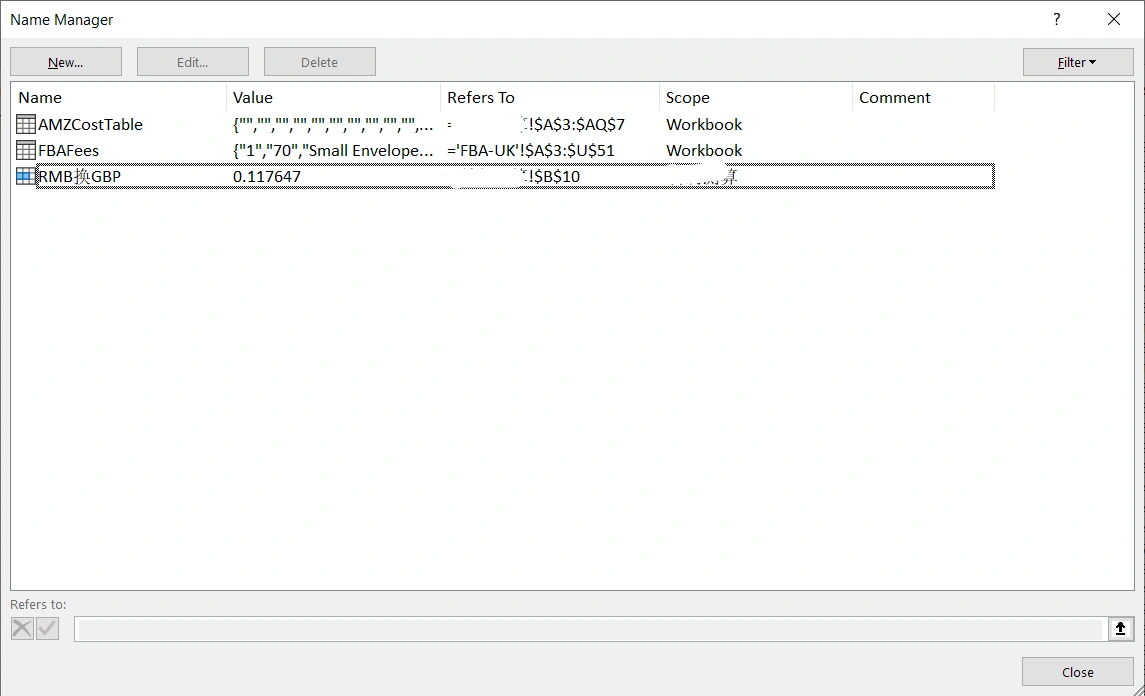
我们可以通过“定义名称”(Define Name)来定义一个新的名称。
函数的实现
在做好基本的数据架构后,我们需要用函数公式来完成需求。
为避免读者嫌我啰嗦,我先直接上公式,如果您需要理解,请继续往下看吧。
这是最终公式:
{=INDEX(FBAFees[UK2],MATCH(1,((LARGE(AMZCostTable[@[L]:[H]],1)+LARGE(AMZCostTable[@[L]:[H]],2))*2<=FBAFees[girth]) * (LARGE(AMZCostTable[@[L]:[H]],1)<=FBAFees[L]) * (LARGE(AMZCostTable[@[L]:[H]],2)<=FBAFees[W]) * (LARGE(AMZCostTable[@[L]:[H]],3)<=FBAFees[H]) * ([@[G.W-kg]]<=FBAFees[weight]),0))}
这个公式中涉及了多个知识点:
1、名称
2、表格
3、INDEX()和MATCH()函数组合
4、LARGE()函数
5、数组公式
6、没了
名称:公式中FBAFees、AMZCostTable是我定义的表格名称,在这里,直接引用了表格的名称而不是表格的位置,如果换成’Sheet2’!$A$3:U$5$1我也是不反对的,只是下次在52行新增了报价信息,是不是还要把函数中的所有区域引用都修改一遍呢?
表格:公式中,涉及两个表格,AMZCostTable和FBAFees,AMZCostTable[@[L]:[H]]表示引用了AMZCostTable同一行的L至H字段,FBAFees[UK2]表示引用了FBAFees表格中字段为UK2的列。如果不用名称和表格,你知道我引用了什么鬼东西吗?
{=INDEX('Sheet2'!$H$3:$H$51,MATCH(1,((LARGE('Sheet1'!$N3:$P3,1)+LARGE('Sheet1'!$N3:$P3,2))*2<='Sheet2'!$B$3:$B$51) * (LARGE('Sheet1'!$N3:$P3,1)<='Sheet2'!$D$3:$D$51) * (LARGE('Sheet1'!$N3:$P3,2)<='Sheet2'!$E$3:$E$51) * (LARGE('Sheet1'!$N3:$P3,3)<='Sheet2'!$F$3:$F$51) * ($S3<'Sheet2'!$G$3:$G$51),0))}
INDEX()和MATCH()函数组合
我不能理解为什么总有人说VLOOKUP是Excel函数之王,好像Excel公式就只剩VLOOKUP似的。在我眼里,与INDEX()+MATCH()函数组合相比,VLOOKUP和HLOOKUP就是垃圾,VLOOKUP的缺点很明显:
1、只能从区域的左往右匹配。
2、还是方向性,VLOOKUP和HLOOKUP是分离的两种方向的应用。
3、由于VLOOKUP采用区域内的相对位移引用,当区域内增加或减少一列时,将可能完全改变VLOOKUP返回的数值。
4、无法快速近似查询,比如从引用列中返回大于查找值的最小值或小于查找值的最大值,有时这个特性对于分段匹配起到了关键作用。
INDEX()和MATCH()完美解决以上问题,并且具有极高的灵活性,最重要的是,INDEX()和MATCH()函数组合在本文中完成了多重条件+分段近似匹配的功能。
数组公式
数组公式是一个比较难理解的功能。数组公式为普通函数再加了一层函数抽象,一个列中每一单位的数值在内层函数运算后的结果输出组成新列作为外层函数的输入,并最终产生新的输出。
举一个简单的例子,A列、B列表示两个向量,现要求他们的点积,即12*15+13*16+14*17,除了用SUMPRODUCT(),如何用数组公式实现?
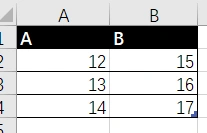
{=SUM(Table1[A]*Table1[B])}
与
=SUMPRODUCT(Table1[A],Table1[B])
将获得同样的结果。
如果用:
{=SUM(PRODUCT(Table1[A],Table1[B]))}
则会将两列中的元素分别相乘再相加。
数组公式就是这样,可以在内存中完成表格间计算,从而避免了大量辅助表格。
多重匹配与数组公式
INDEX()和MATCH()搭配数组公式,是本文的灵魂,也是分段匹配的灵魂,为了简化理解,在此我再举一个例子。
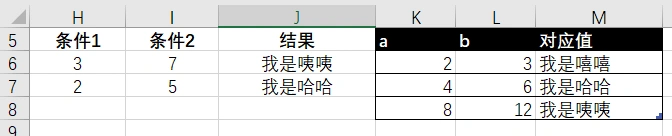
现有一组对应值,当条件1小于2且条件2小于3时,对应结果为我是嘻嘻,否则继续匹配条件。
{=INDEX(Table2[对应值],MATCH(1,(H6<Table2[a])*(I6<Table2[b]),0))}
公式依次运算:
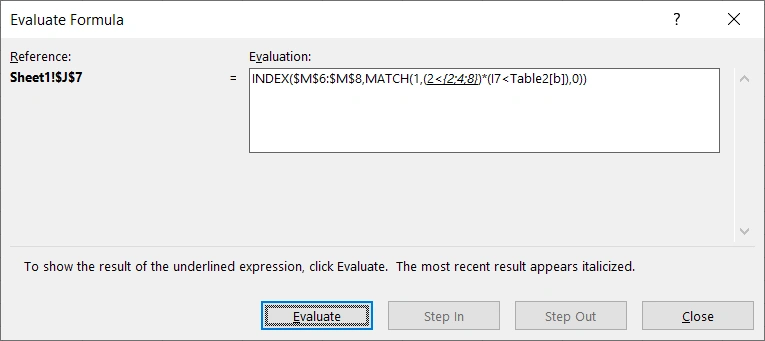
将名称对应区域,运算第一个比较H7<Table2[a]),即2<{2;4;8}。3将与数列中的数值依次比较,并返回比较结果,即{FALSE;TRUE;TRUE}:
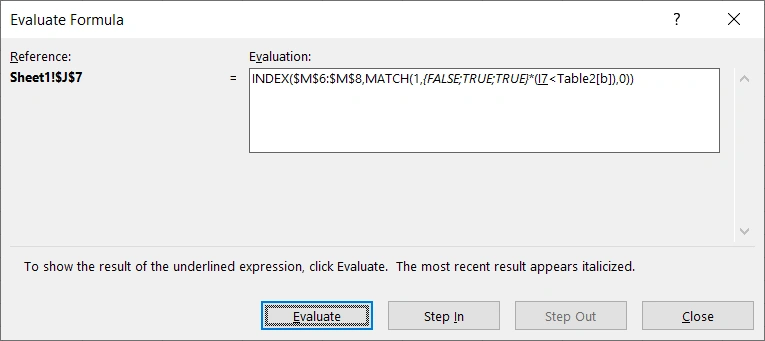
再比较I7<Table2[b],即5<{3;6;12};
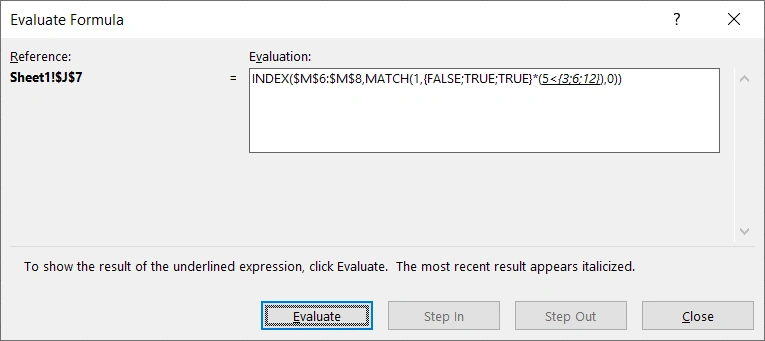
获得结果{FALSE;TRUE;TRUE}。
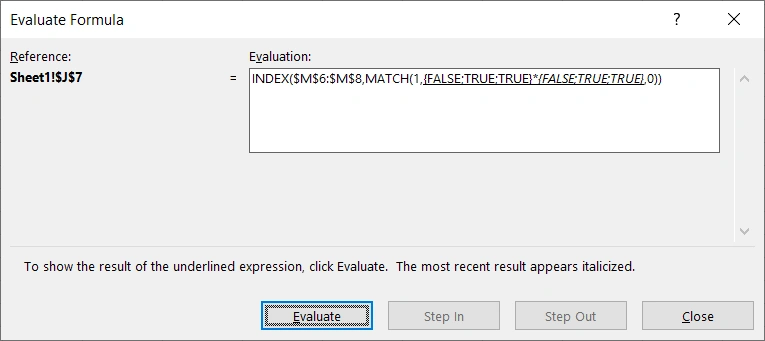
在Excel中,FALSE代表0,TRUE代表1,对{FALSE;TRUE;TRUE}和{FALSE;TRUE;TRUE}做点积,获得{0;1;1}。
FALSE与TRUE的点积运用涉及到了逻辑知识,两个布尔值相乘,只有都为TRUE时才为TRUE,否则为FALSE,理解为逻辑的话就是两个条件都为真时才为真,也即上述的条件1和条件2都满足时才为TRUE,即1。最终MATCH()函数实际输入的参数为:
MATCH(1,{0;1;1},0)
即在数列{0;1;1}中匹配1的位置,在这里使用0作为匹配规则,即完全匹配,MATCH()将会返回第一个数列中完全匹配的元素位置,由于原始的对应表是从上到下依次递增,因此位置是有效的,最后MATCH(1,{0;1;1},0)返回了数值2。
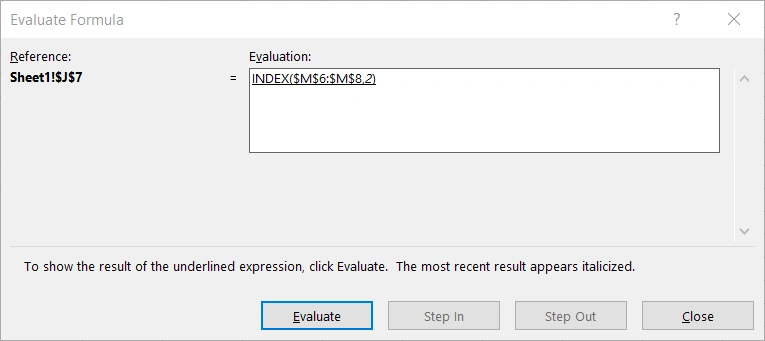
MATCH(1,{0;1;1},0)返回的数值2作为INDEX()的参数,将返回$M$6:$M8中的第二行,即“我是哈哈”。
这就是INDEX()与MATCH()函数组合的数组公式的全部运算过程。
LARGE()
LARGE()和SMALL()可以实现同样的效果,LARGE(range,n)表示从range区域中获得第n大的数值,我们可以用这个方式动态识别第一长和第二长的边,就实现了长宽高位置的容错。
最后,将上述的全部原理带入回上文开头的公式,就不难理解为什么是这样的了:
{=INDEX(FBAFees[UK2],MATCH(1,((LARGE(AMZCostTable[@[L]:[H]],1)+LARGE(AMZCostTable[@[L]:[H]],2))*2<=FBAFees[girth]) * (LARGE(AMZCostTable[@[L]:[H]],1)<=FBAFees[L]) * (LARGE(AMZCostTable[@[L]:[H]],2)<=FBAFees[W]) * (LARGE(AMZCostTable[@[L]:[H]],3)<=FBAFees[H]) * ([@[G.W-kg]]<=FBAFees[weight]),0))}
只需要简单替换FBAFees[UK2]中的字段,就可以对表格中的其他字段进行分段匹配,获得其他区域报价或者包裹类型。
以上就是全部内容,感谢您的阅读。
Excel结合Power Query,可以做很多天马行空的事情,上个星期,我用Excel结合Power Query,做了一个简单的工作流程监控系统,并且做了BI统计,从而实现了个人工作的统筹管理。Excel可以像数据库一样建表和建立数据模型,是最简单的建模软件之一,通过Power Query和Power Pivot实现数据导入、清洗、转换、透视与逆透视、聚合、统计和其他数据分析要求,当使用Excel建立的数据模型足够完善时,也可以比较容易地导入到真正的数据库系统或者Power BI中。
通过此文我发现解释一个实现比实现需要花更多更多的时间,如果读者希望我以后继续发布这样的文章,请随时给我点赞、留言、投币鼓励我,也欢迎提出更有意思的见解。
大家晚安。